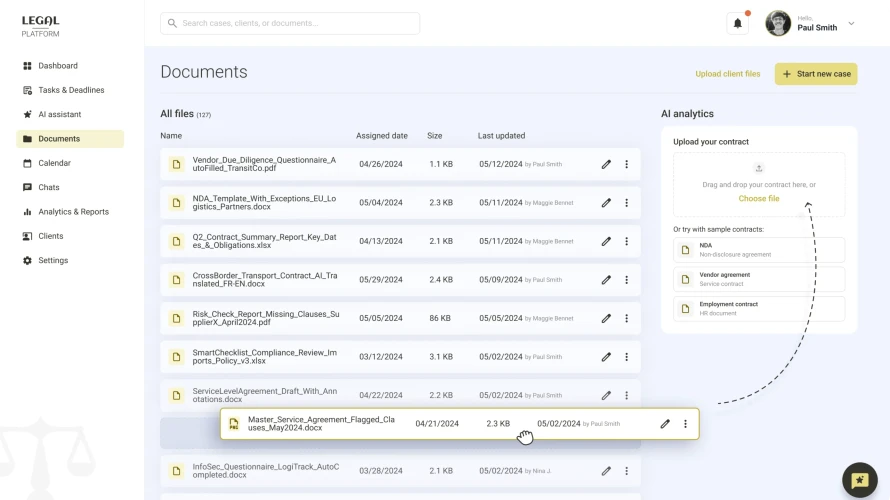
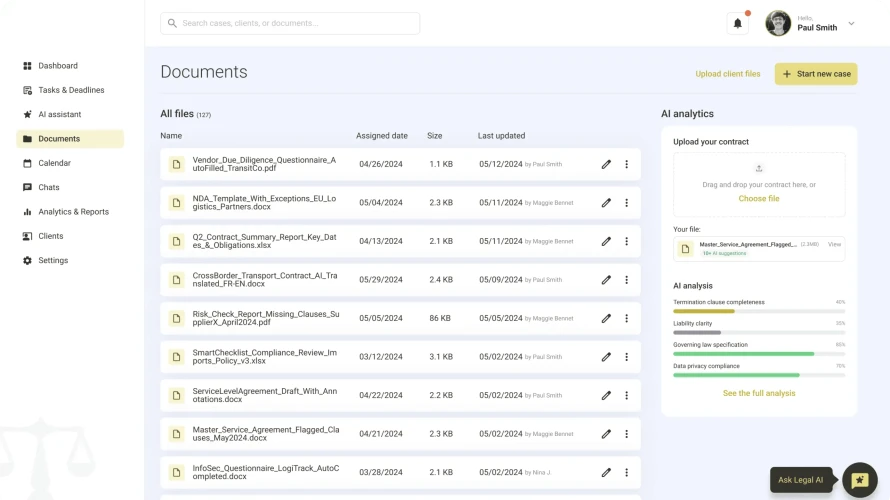
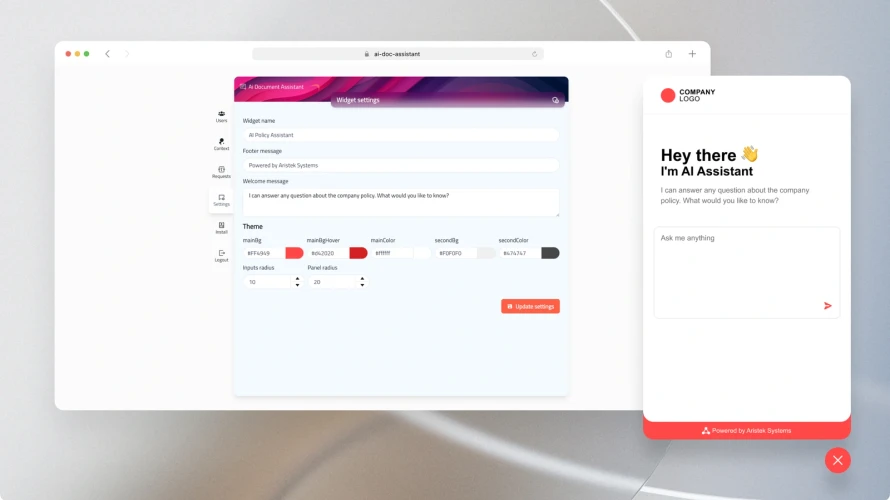
Data Engineering Services
Automate your data pipeline with data engineering services. Get infrastructure for automatically processing your data into data warehouses or data lakes.
23+
years of custom software development
5+
years of AI & DS expertise
160+
in-house employees